Research proposal
Abstract
Constantly, around the clock, reconnaissance is conducted for vulnerable systems and services around the world. This is done manually or automated by malicious actors and can be more or less systematic. To carry out these reconnaissance, tools are often included that are illegal to use in many countries. It could be, for example, port scanning, various types of lookups or attempts to brute force login details for a specific system or service. In order for the malicious actors to maintain anonymity, a common approach is that these enumeration and intrusion attempts are carried out via a network that hide the identity of the user. To detect intrusions or suspicious activities in a private network, an IDS (Intrusion Detection System) or an IPS (Intrusion Prevention System) can be used. These systems monitor the network traffic and can prevent or alert if suspicious activity is found. If these protection mechanisms can classify and filter malicious traffic, for example from the Tor or I2P networks, it is possible to prevent intrusions at an early stage.
Introduction
The use of anonymous networks is common today for several different reasons. As these networks provide anonymity for the user, they are also popular to use for malicious actors who exploit the anonymity for illegal activities [9][15][4][12]. According to [13] the issue of whether or not an intruder will breach an outer perimeter is more a question of when rather than if.
One of the largest and most well-known of these type of network is Tor. According to Tor project the network has two main properties:
– “Your internet service provider, and anyone watching your connection locally, will not be able to track your
internet activity, including the names and addresses of the websites you visit”.
– “The operators of the websites and services that you use, and anyone watching them, will see a connection coming from the Tor network instead of your real Internet (IP) address, and will not know who you are unless you explicitly identify yourself” [14].
As their is a very high degree of all malicious actors that use anonymous networks, it is also relevant to be able to protect against these types of connections, “anonymous traffic analysis and classification is an important part of maintaining network security” [8]. The protection could be integrated with an IPS/IDS [1] or alternatively function independently. Another option is to integrate the protection mechanism into a software IDS with machine learning as described in [5]. In this research proposal, however, how the technical integration takes place will not be in focus.
Research concepts
Restrict access to resources is a fundamental requirement for open networks such as the Internet. Restriction can be done in several ways and one of the most common that most people know is through login with username and password. Being able to detect and prevent intrusion attempts into access-protected networks is a fundamental and important part of information security. This is not only applicable to applications and systems that are access protected. That is, where confidentiality and privacy need to be protected. But is also useful for, for example, web applications that want to protect themselves against malicious traffic where you want to strive for high availability. Rules for these protections could then be configured in a firewall, IPS/IDS or in a WAF.
Research concepts include how network traffic and connection attempts can be classified and filtered. The goal is to determine through a probability assessment whether a connection goes through a proxy-based network. The data on which this assessment is based consists of collected data from the connection. Speed, port, protocol and IP address are variables that will be assessed.
The IP address will be used to check whether an address is restricted or not. Based on the IP address, meta data can also be produced such as which country the address originates from. This can be used for other restrictions. For example, if you want to limit connections from certain countries.
For a long time, it has been common to restrict connections to certain IP-addresses in order to protect assets. Concepts in this review is about how and which methods can be used for detecting network traffic from malicious proxy-based networks. That are available in combination with IP-blocking/restriction technique.
Literature review
In the literature review, there are several theories about how network traffic can be classified and filtered.
Several studies focus on measuring the latency in the TCP handshake process [2], [3], [7]. Connections with a deviant latency can be signs that a connection originates from a proxy-based network. Other studies apply machine learning to an IPS to detect anomalies in a network [10], [16]. However, this requires the machine learning model to use specific algorithms. Developed and established algorithms used are PCA, Decision Tree Classifier and ResNet. However, there are no conclusions about which algorithm performs best for this purpose.
Most of the studies in the literature review focus on connections from the TOR network. However, there are other proxy based networks that offer anonymity. One of these is I2P which uses the NTCP protocol. In the study by [17], they study the possibilities of assessing whether a connection uses this protocol. This is because the network traffic is classified through 4 algorithm models, NaiveBayes, BayesNet, SVM and RandomForest. Each study focuses primarily on a part of the research problem and some are only theoretically applicable. In order to provide protection and prevent connections from malicious networks, the protection must be able to work regardless of which network the connection comes from. This also needs to be able to function in real time.
Research method
In order to get several different connections from different parts of the world, a global cloud provider can be used. Clients can be started from different data centers at different times. The connection speed also needs to be adapted as generally all cloud providers offer very fast connections (>10 Mbps). To reduce the speed for a client, the network settings need to be changed, for example by setting a max speed of 2 Mbps to be able to measure a slow connection. Exactly which settings need to be implemented needs to be evaluated before the test. The connection speed for each client also needs to be verified before starting the test. To get a structured measurement, the clients should be grouped by location and connection speed. Only one group of clients is evaluated and tested at a time. Before a test can start, you need to verify that the measuring tool is activated and ready to start the measurement. Network monitoring tools like Wireshark or Tcpdump [6] should also be installed and activated.
The measuring tool will save the raw data to a log file with each new connection. Each entry in the log file will consist of: Time stamp, TCP event type, Source port, Source address, Destination port, Size of data, Rating value. The rating value will only be saved for certain TCP events. These log files will be saved and categorized by client group as they are generated. The data in the files will be the basis for further analysis
Quantitative research and Structural equation modeling
For this research project a quantitative research method will be chosen. By using a quantitative research
method, a systematic evaluation takes place through the collection of quantifiable data from purposive samples.
The approach will be a correlational research between calculated values to study correlations. By using this approach, it is important to study the correlations to avoid incorrect conclusions. One way could be to use Structural equation modeling (SEM) as described in [11]. A possible SEM model could look like Figure 1.
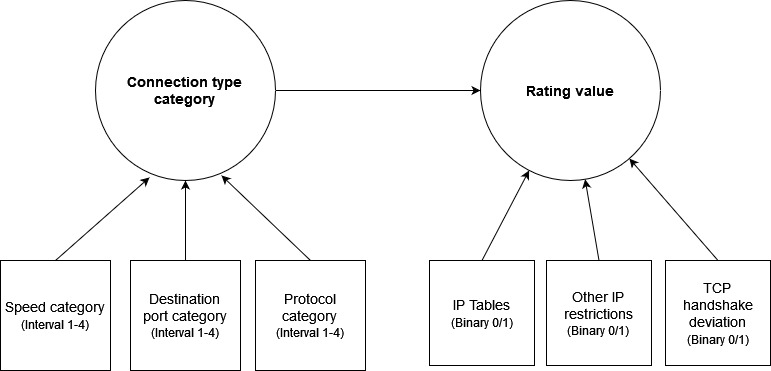
In order to determine a connection type category, the measurable variables need to be categorized and numbered.
Speed (interval 1-4) – Slow, medium slow, medium high, high. For instance, a connection < 2 mbps could be slow and > 100 mbps high.
Destination port (range 1-4) – FTP, Web, SSH and Mail.
Protocol (range 1-4) – UDP, TCP, NTCP, Unknown.
Regarding variables for rating value
The rating value is an interval between 0 to 100. A value of 100 can be interpreted as an absolute certainty that this is a connection from an anonymous network. There are several parameters / variables that form the basis for the calculation of the rating value. Connection type category, IP table lookup, other IP restrictions and deviations in the TCP handshake.
IP tables (binary value) – If this is true (=1) it means that the IP-address is existing in the exit node restriction list. The rating value should return 100.
Other IP restrictions (binary) – If this value is applied it could for example be that the origin of the IP-address is coming from a restricted area or country. If this is true, the rating value should return 100.
TCP handshake deviation (binary) – This value indicate if their are any deviations in the TCP-handshake process. This value cannot be applied to all connection type categories depending on which protocols are used. For instance their are not any handshake process in the UDP protocol. This value, regardless of whether it is true or false, must together with the connection type category form the basis for the probability calculation of the rating value.
Examples of distribution of rating values for different variable values is shown in figure 2.
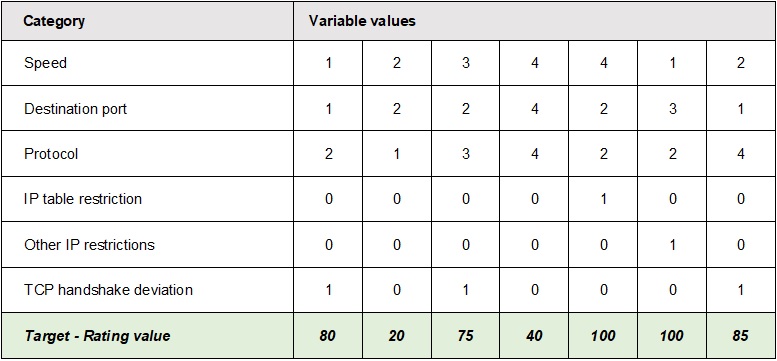
Data collected needs to be combined to find variations, correlations and error deviations. The rating value is the primary data point and other data is considered meta data. In a first step, a univariate analysis is performed by calculating the mean, median, range and frequency of the rating value. The data then needs to be grouped and categorized for further visualization and presentation.
Research plan
The research plan is divided into 5 stages. The entire plan extends over a period of 3 months (12 weeks).
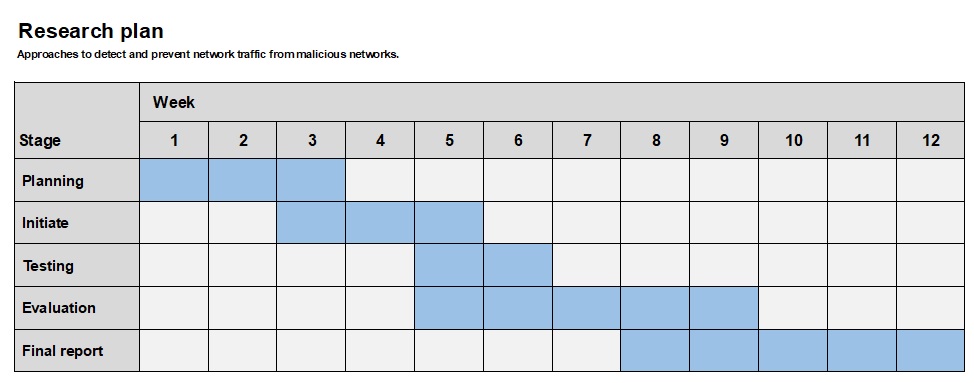
Details about each stage in the plan:
- Planning – Evaluate which software should be used and any technical requirements for hardware. Evaluate which cloud service provider can be used. Plan how each client will be installed and configured according to the predetermined requirements. Create test protocols that can be used during testing. Determine the format of generated data that will be the basis for data analysis.
- Initiate – Create the technical conditions. Clients and software need to be installed and configured. Cloud data services needs to be created and configured.
- Testing – Start testing according to the test protocols. At this stage, raw data will be generated that will be used in the evaluation process.
- Evaluation – Based on the collected data, analyzes can be carried out. This can be started before the entire testing phase is completed. Any adjustments in the testing may also be necessary, therefore the evaluation should be started as early as possible.
- Final report – Find conclusions and write the final report.
References
References
[1] Uzair Bashir and Manzoor Chachoo. “Intrusion detection and prevention system: Challenges opportunities”. In: 2014 International Conference on Computing for Sustainable Global Development (INDIACom).2014, pp. 806–809. doi: 10.1109/IndiaCom.2014.6828073.
[2] Zechun Cao and Shou-Hsuan Stephen Huang. “Detecting Intruders and Preventing Hackers from Evasion by Tor Circuit Selection”. In: 2018 17th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/ 12th IEEE International Conference On Big Data Science And
Engineering (TrustCom/BigDataSE). 2018, pp. 475–480. doi: 10 . 1109 / TrustCom / BigDataSE . 2018 .
00074.
[3] P Carvalho et al. “Detection of Anonymised Traffic: Tor as Case Study”. In: (2020).
[4] M. Chertoff and T. Simon. “The impact of the dark Web on Internet governance and cyber security”. In:
(2015).
[5] Xianjin Fang and Lingbing Liu. “Integrating Artificial Intelligence into Snort IDS”. In: 2011 3rd Interna-
tional Workshop on Intelligent Systems and Applications. 2011, pp. 1–4. doi: 10.1109/ISA.2011.5873435.
[6] Piyush Goyal and Anurag Goyal. “Comparative study of two most popular packet sniffing tools-Tcpdump and Wireshark”. In: 2017 9th International Conference on Computational Intelligence and Communication Networks (CICN). 2017, pp. 77–81. doi: 10.1109/CICN.2017.8319360.
[7] Shou-Hsuan Stephen Huang and Zechun Cao. “Detecting Malicious Users Behind Circuit-Based Anonymity Networks”. In: IEEE Access 8 (2020), pp. 208610–208622. doi: 10.1109/ACCESS.2020.3038141.
[8] Jia Lingyu et al. “A hierarchical classification approach for tor anonymous traffic”. In: 2017 IEEE 9th
International Conference on Communication Software and Networks (ICCSN). 2017, pp. 239–243. doi:
10.1109/ICCSN.2017.8230113.
[9] S. Mancini and L. A. Tomei. “The dark Web: Defined discovered exploited”. In: Int. J. Cyber Res. Edu.
1.1 (2019), pp. 1–12. [10] Oyeyemi Osho, Sungbum Hong, and Tor A. Kwembe. “Network Intrusion Detection System Using Principal Component Analysis Algorithm and Decision Tree Classifier”. In: 2021 International Conference on Computational Science and Computational Intelligence (CSCI). 2021, pp. 273–279. doi: 10 . 1109 / CSCI54926.2021.00117.
[11] Jeanne Ellis Ormrod Paul D. Leedy. In: Practical research : planning and design. Vol. 11. 2015.
[12] Javeriah Saleem, Rafiqul Islam, and Muhammad Ashad Kabir. “The Anonymity of the Dark Web: A
Survey”. In: IEEE Access 10 (2022), pp. 33628–33660. doi: 10.1109/ACCESS.2022.3161547.
[13] Rodd Sapp Bill Searcy Dhimant Desai Chris Blask John Bone Scott Spiker Tom Patterson Ed Liebig. “Enhancing National Cybersecurity: The Current and Future States of Cybersecurity in the Digital Economy”. In: Unisys Corporation (2016), p. 35.
[14] TOR Project – How TOR works. https://tb-manual.torproject.org/about/. Accessed: October 28,
2022.
[15] G. Weimann. “Going dark: Terrorism on the dark Web”. In: Stud. Conflict Terrorism 39.3 (2016), pp. 195–206.
[16] Zhonghan Xu and Ming Liu. “An Intrusion Detection Method based on PCA and ResNet”. In: 2021
3rd International Conference on Applied Machine Learning (ICAML). 2021, pp. 52–56. doi: 10.1109/
ICAML54311.2021.00019.
[17] Hongshan Yin and Yongzhong He. “I2P Anonymous Traffic Detection and Identification”. In: 2019 5th
International Conference on Advanced Computing Communication Systems (ICACCS). 2019, pp. 157–
162. doi: 10.1109/ICACCS.2019.8728517.